Introduction
If you find yourself doing data analysis in Python, you should check out siuba. siuba is a port of the R package dplyr, but you don’t need to know any R to get started.
siuba implements a domain specific language for querying data. You can use siuba to query both local Python data frames and remote SQL databases.
Why a new “language” and not the pandas API?
concise lambdas and tab-completion
consistent output for common operations
unified API for grouped and ungrouped data frames
All of these advantages and more are described by Michael Chow in his list of key features.
Let’s walk through each case with some example data.
from siuba import *
from siuba.data import mtcars
import pandas as pd
bridges = pd.read_csv("maryland_bridges.csv")Concise lambdas with tab-complete
siuba introduces the symbol _. You can think of _ as a placeholder or pronoun
for the actual name of the data.
So instead of writing bridges.yr_built you can write _.yr_built in any
data frame or siuba function.
In many ways, _ behaves like a concise lambda:
bridges[_.yr_built > 1990]bridges[lambda _: _.yr_built > 1990]And this new “lambda” doesn’t just save a few characters: it also supports tab-completion in IPython and Jupyter Notebooks, suggesting column names and pandas data frame and series methods:
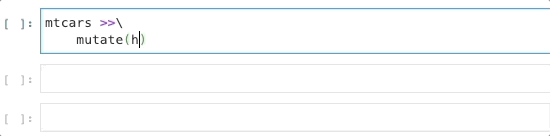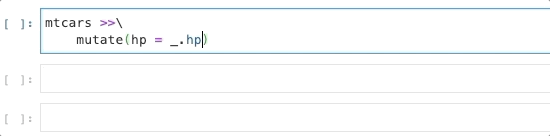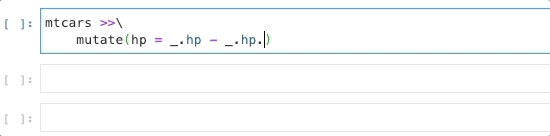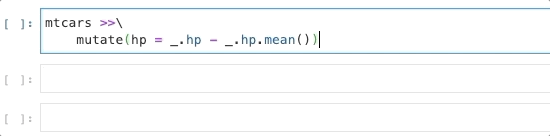
This was my small contribution to Siuba, with lots of help from Michael Chow. Include the following to try it out!
import siuba.experimental.completerConsistent output for common operations
Calculating the size of groups is a very common operation.
siuba makes this, and many other queries straightforward by providing
helpers like
count and distinct and by
simplifying the API to 5 common actions.
Additionally, siuba output is always consistent. siuba never returns MultiIndex data frames, which has its own API and idiosyncrasies.
(bridges >>
count(decade=10 * (_.yr_built // 10), sort=True) >>
head())## decade n
## 0 1970 404
## 1 1960 319
## 2 1980 304
## 3 1990 279
## 4 1950 261(
bridges
.assign(decade=lambda _: 10 * (_.yr_built // 10))
.groupby("decade")
.agg(n = ("decade", "size"))
.reset_index()
.sort_values("n", ascending=False)
.head()
)## decade n
## 12 1970 404
## 11 1960 319
## 13 1980 304
## 14 1990 279
## 10 1950 261Unified group API
When working with groups in pandas, you often have to juggle both the grouped
and ungrouped data frame. Additionally, panda’s grouped API has some subtle
differences, such as the transform method shown below.
All of siuba’s core actions have consistent behavior in grouped and ungrouped data frames.
(mtcars >>
group_by(_.cyl) >>
mutate(hp=_.hp - _.hp.mean()) >>
ungroup())mtcars_cyl = mtcars.groupby("cyl")
(
mtcars
.assign(hp=mtcars_cyl.obj.hp - mtcars_cyl.hp.transform("mean"))
)